
【ai模型】判断语句的积极性与消极性
🤖 模型库
Hugging Face 是一个流行的自然语言处理 (NLP) 模型库和社区,提供了大量预训练模型、工具和资源,使得 NLP 的开发者和研究人员能够快速高效地构建和应用各种文本相关应用。在这里,快速熟悉 Hugging Face 的基本功能,并展示一些简单实用的例子。
huggingFace官方研发了一比肩chatgtp3.5 的 ai产品
🚀 快速使用
1、安装 Hugging Face
1 | pip install transformers |
2、安装 PyTorch
PyTorch(torch): 是一个开源的机器学习库,广泛用于深度学习任务。它提供了张量运算和神经网络的支持,是构建深度学习模型的强大工具。
torchaudio: 是 PyTorch 的一个附加库,专注于音频处理任务。它提供了处理音频数据的工具和函数,方便在 PyTorch 中进行声音相关的深度学习任务。
1 | pip install torch torchaudio |
3、浏览 Hugging Face 的 模型库
找到适合你项目需求的模型。
可以通过搜索或筛选来缩小范围。
点击模型名称进入模型主页,可以查看模型的详细信息、用法示例、源代码等
比如:我们选择模型
distilbert-base-uncased-finetuned-sst-2-english,该模型能判断文本的情绪
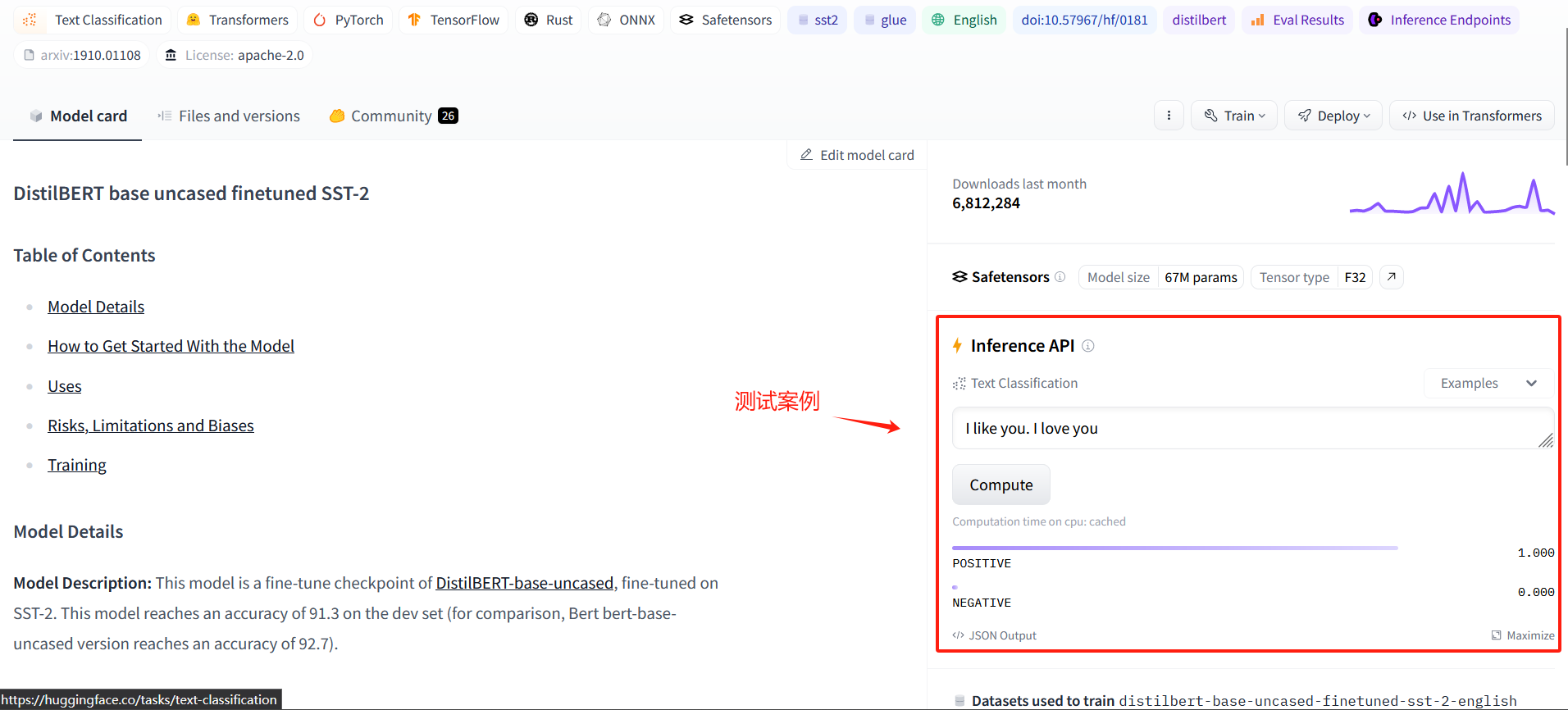
4、下载并使用模型
1 | # 使用 from transformers import MODEL_NAME 导入模型。 |
输出结果
1 | # 积极的,分数为0.54 |
1 | # 消极的,分数为1.00 |
5、远程调用模块
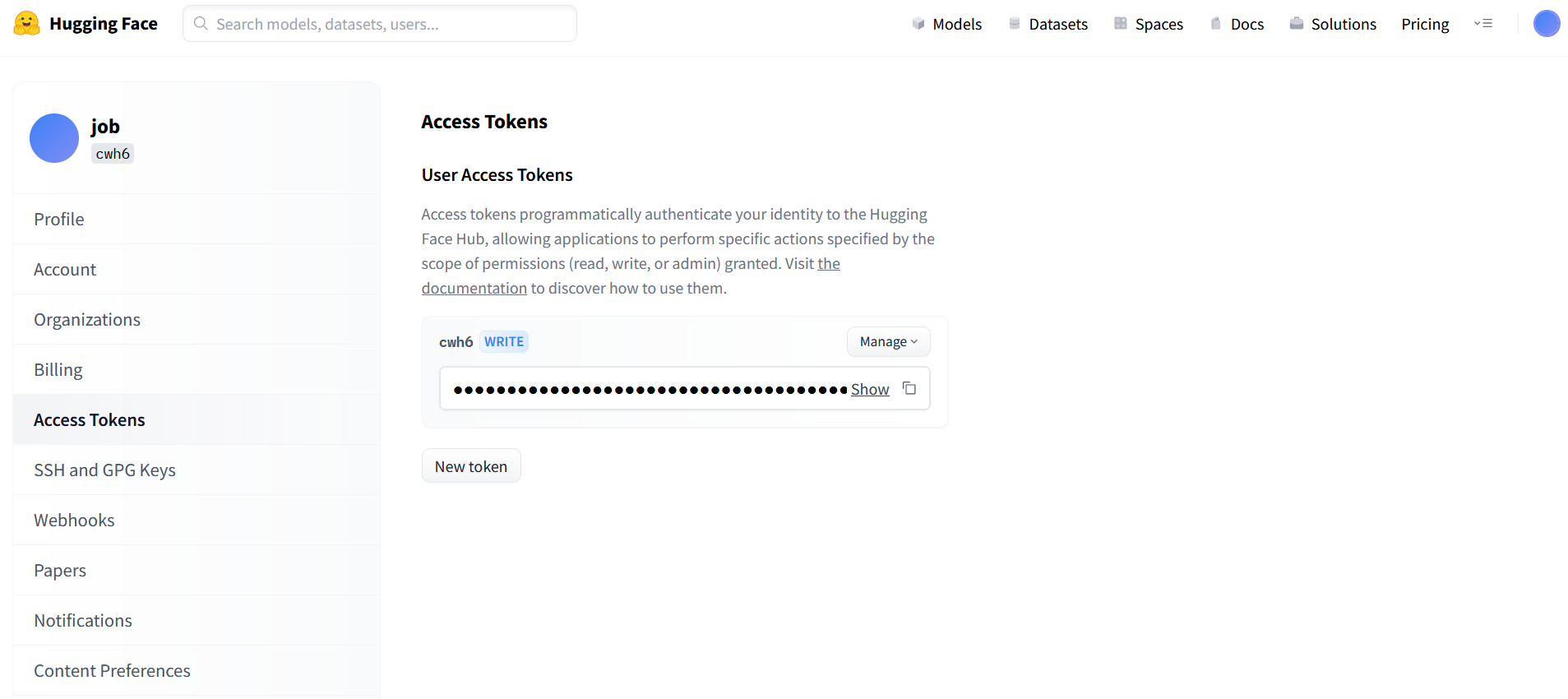
1、申请token
2、获取远程接口
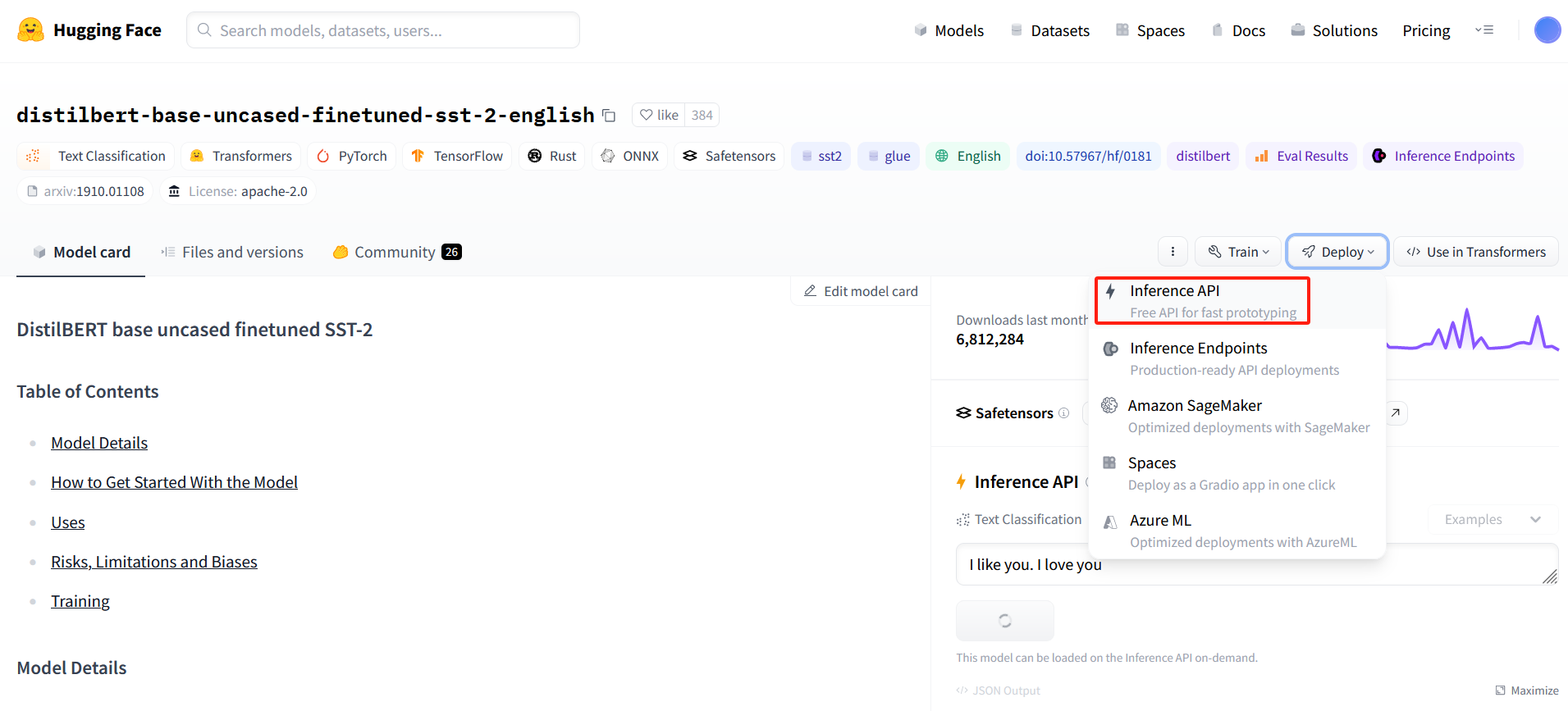
选择合适的语言就行
下面采用python
1 | import requests |
输出结果
1 | # 积极情绪大于消极情绪 |
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.